IBM Dynamical Decoupling Optimizations with Superstaq - Comparison
Dynamical decoupling (DD) is an error mitigation technique used to suppress noise added to computation from system-environment interaction (i.e. decoherence error). DD is implemented during algorithm execution by adding special gate sequences that are equal to the identity operation in periods of qubit idling. Examples of DD sequences include XX, XY4, XY8, and UDD, among others.
Below is a brief tutorial on Superstaq dynamical decoupling optimizations for the IBM family of superconducting quantum devices. In the example, the CPMG sequence, XX, will be used. CPMG, referred to as dynamic is our default DD strategy.
Many research articles can be found that describe the variations and benefits of DD. For more information about IBM Quantum, visit their website here.
Imports and API Token
This example tutorial notebook uses qiskit-superstaq, our Superstaq client for Qiskit; you can try it out by running pip install qiskit-superstaq.
[1]:
# Required Superstaq imports
try:
import qiskit
import qiskit_ibm_provider
import qiskit_superstaq as qss
except ImportError:
print("Installing qiskit-superstaq...")
%pip install --quiet 'qiskit-superstaq[examples] qiskit-ibm-provider'
print("Installed qiskit-superstaq.")
print("You may need to restart the kernel to import newly installed packages.")
import qiskit
import qiskit_ibm_provider
import qiskit_superstaq as qss
To interface Superstaq via Qiskit, we must first instantiate a provider in qiskit-superstaq with SuperstaqProvider(). We then supply a Superstaq API token (or key) by either providing the API token as an argument of qss.SuperstaqProvider() or by setting it as an environment variable (see more details here).
[2]:
# Get the qiskit superstaq provider for Superstaq backend
# Provide your api key to the using the "api_key" argument if
# SUPERSTAQ_API_KEY environment variable is not set.
provider = qss.SuperstaqProvider()
This notebook will target IBM’s 16-qubit Guadalupe device.
[3]:
backend = provider.get_backend("ibmq_guadalupe_qpu")
To submit jobs to the IBM machine, we will use an IBMProvider. This will require qiskit-ibm-provider and an accout on IBM Quantum.
[4]:
ibm_provider = qiskit_ibm_provider.IBMProvider()
ibm_backend = ibm_provider.get_backend("ibmq_guadalupe")
Example 1: Circuit Compilation and DD Optimization with Superstaq
We will start by creating a circuit generator using Qiskit. In this example, we will use the Bernstein Vazirani (BV) algorithm to find the secret string of all ones ( i.e. ‘11…1’):
[ ]:
def create_bv(circuit_width: int) -> qiskit.QuantumCircuit:
qc = qiskit.QuantumCircuit(circuit_width, circuit_width - 1)
for i in range(circuit_width - 1):
qc.h(i)
qc.x(circuit_width - 1)
qc.h(circuit_width - 1)
for i in range(circuit_width - 1):
qc.cx(i, circuit_width - 1)
qc.barrier()
for i in range(circuit_width):
qc.h(i)
for i in range(circuit_width - 1):
qc.measure(i, i)
return qc
We can draw the circuit using qiskit:
[6]:
qc_4 = create_bv(4)
qc_4.draw("mpl")
[6]:
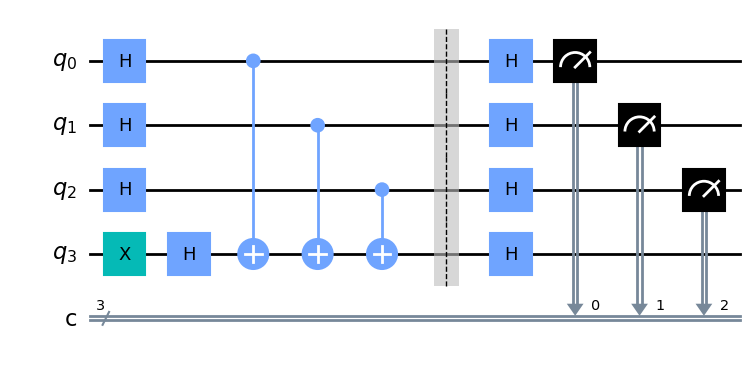
Next, we will compile the logical circuit with Qiskit. Qiskit compilation will serve as a baseline that we use to evaluate Superstaq’s performance.
[7]:
qiskit_qc_4_optimized = qiskit.transpile(qc_4, ibm_backend, optimization_level=3)
qiskit_qc_4_optimized.draw("mpl", fold=-1, idle_wires=False, justify="right")
[7]:
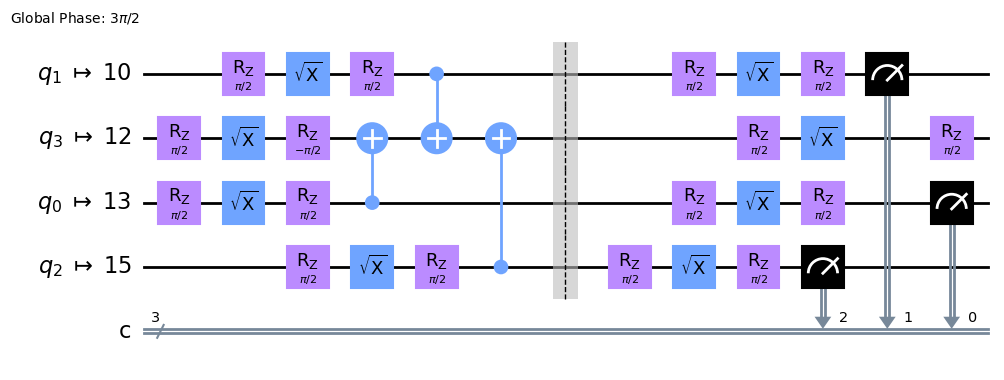
Superstaq compilation transforms the circuit so that it uses optimized instructions. To implement error mitigation with default dynamic DD, we add additional XX gates to the circuit. These are CPMG DD sequences.
[8]:
ss_qc_4_optimized = backend.compile(qc_4, dynamical_decoupling=True)
ss_qc_4_optimized.pulse_gate_circuit.draw("mpl", fold=-1, idle_wires=False, justify="right")
[8]:

Example 2: Real Quantum Machine Results
Here, we will show how Superstaq compares to Qiskit’s optimization_level = 3 on modestly sized circuits. First, let’s create a seven-qubit BV benchmark:
[9]:
qc_7 = create_bv(7)
qc_7.draw("mpl")
[9]:
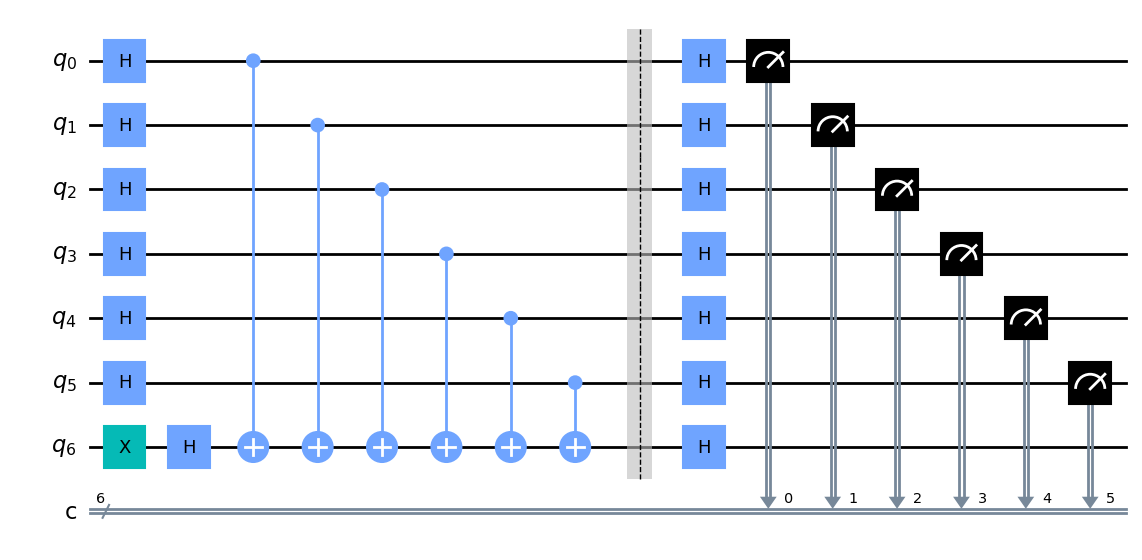
Qiskit optimization_level = 3 transpilation:
[10]:
qiskit_qc_7_optimized = qiskit.transpile(qc_7, ibm_backend, optimization_level=3)
qiskit_qc_7_optimized.draw("mpl", fold=-1, idle_wires=False, justify="right")
[10]:
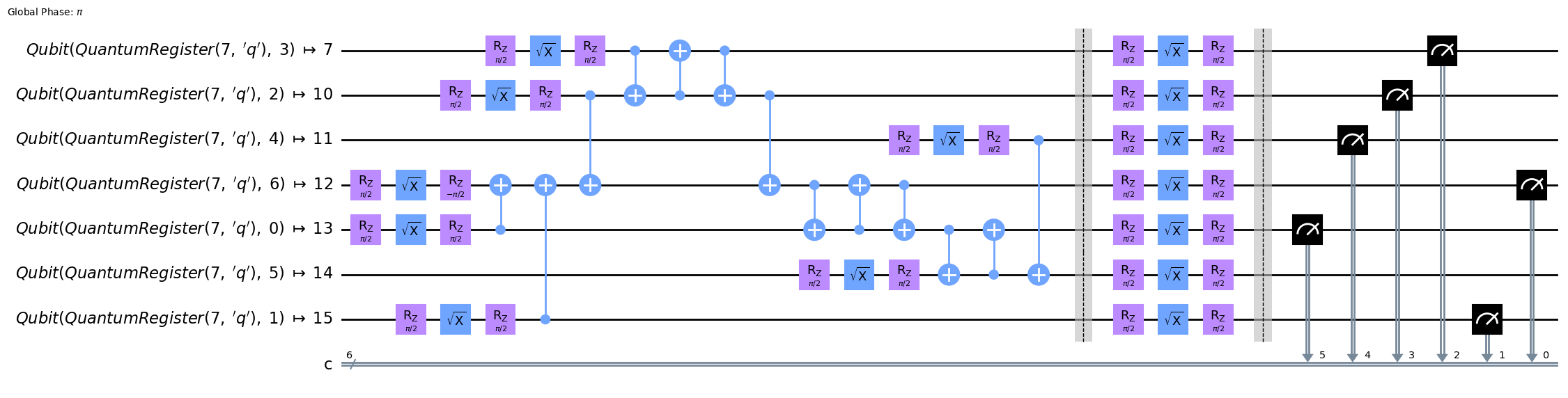
Superstaq optimized compilation with dynamic DD:
[11]:
ss_qc_7_optimized = backend.compile(qc_7, dynamical_decoupling=True)
ss_qc_7_optimized.pulse_gate_circuit.draw("mpl", fold=-1, idle_wires=False, justify="right")
[11]:

Finally, circuit execution on IBM Guadalupe:
[12]:
job_7 = ibm_backend.run([ss_qc_7_optimized.pulse_gate_circuit, qiskit_qc_7_optimized], shots=4000)
[13]:
counts_7 = job_7.result().get_counts()
qiskit.visualization.plot_histogram(
counts_7, legend=["ss-dd", "qiskit"], number_to_keep=10, figsize=(11, 5)
)
[13]:
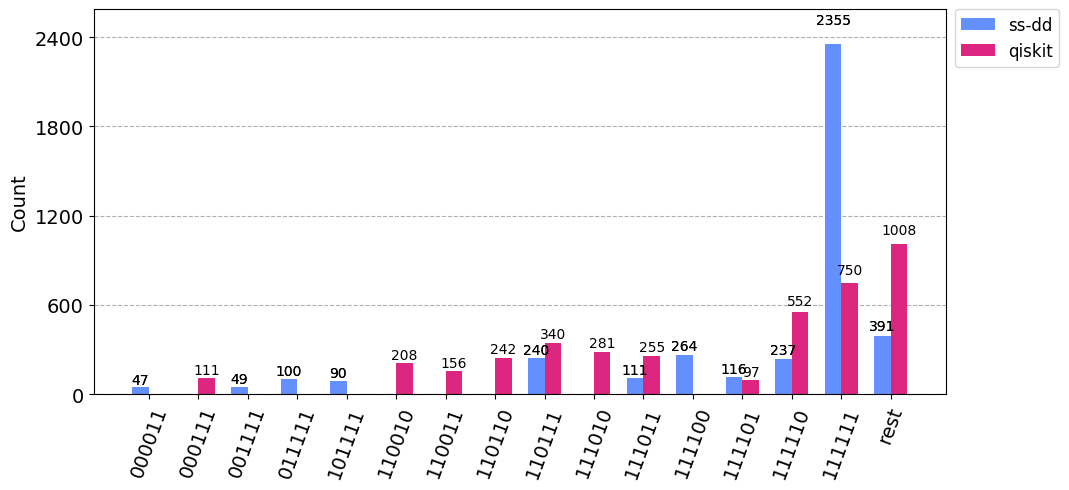
The correct answer is ‘111111,’ and we can see that Superstaq offers dramatic improvements! More than 3.1x in terms of probability of success and about 6.5x in terms of relative strength.
Let’s try again with nine qubits!
First, create:
[14]:
qc_9 = create_bv(9)
qc_9.draw("mpl")
[14]:
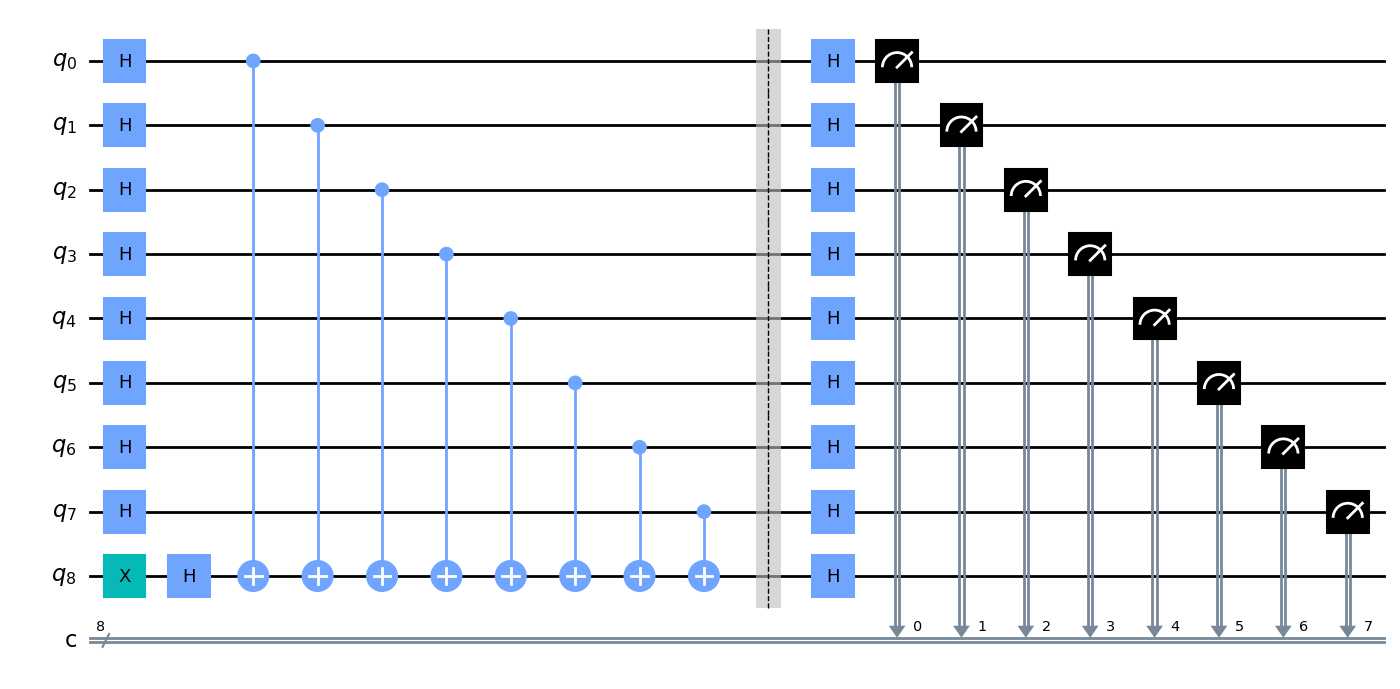
Second, Qiskit transpile:
[15]:
qiskit_qc_9_optimized = qiskit.transpile(qc_9, ibm_backend, optimization_level=3)
qiskit_qc_9_optimized.draw("mpl", fold=-1, idle_wires=False, justify="right")
[15]:
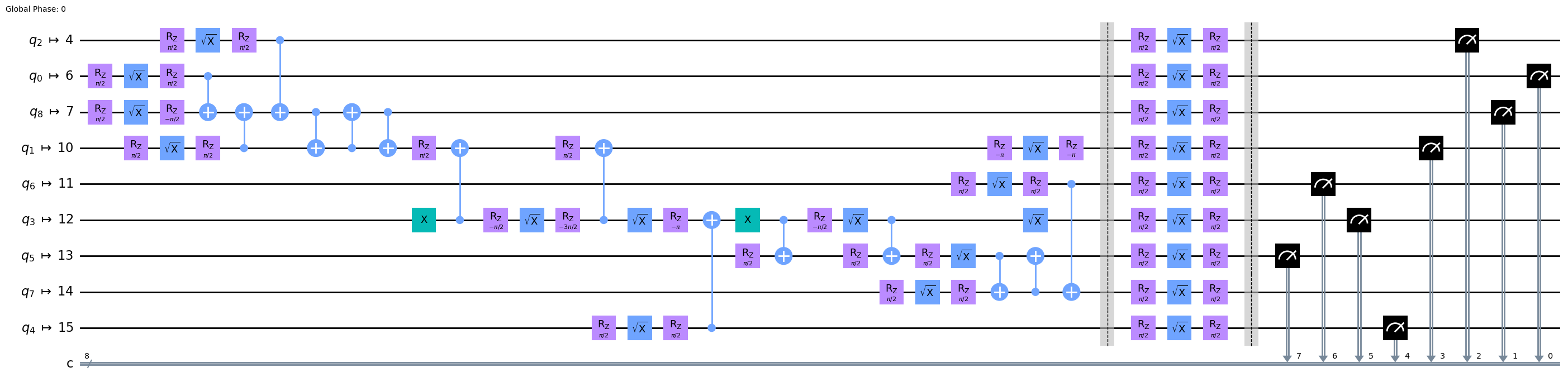
Third, Superstaq optimize with DD:
[16]:
ss_qc_9_optimized = backend.compile(qc_9, dynamical_decoupling=True)
ss_qc_9_optimized.pulse_gate_circuit.draw("mpl", fold=-1, idle_wires=False, justify="right")
[16]:

Last, real machine run.
[17]:
job_9 = ibm_backend.run([ss_qc_9_optimized.pulse_gate_circuit, qiskit_qc_9_optimized], shots=4000)
[18]:
counts_9 = job_9.result().get_counts()
qiskit.visualization.plot_histogram(
counts_9, legend=["ss-dd", "qiskit"], number_to_keep=10, figsize=(11, 5)
)
[18]:
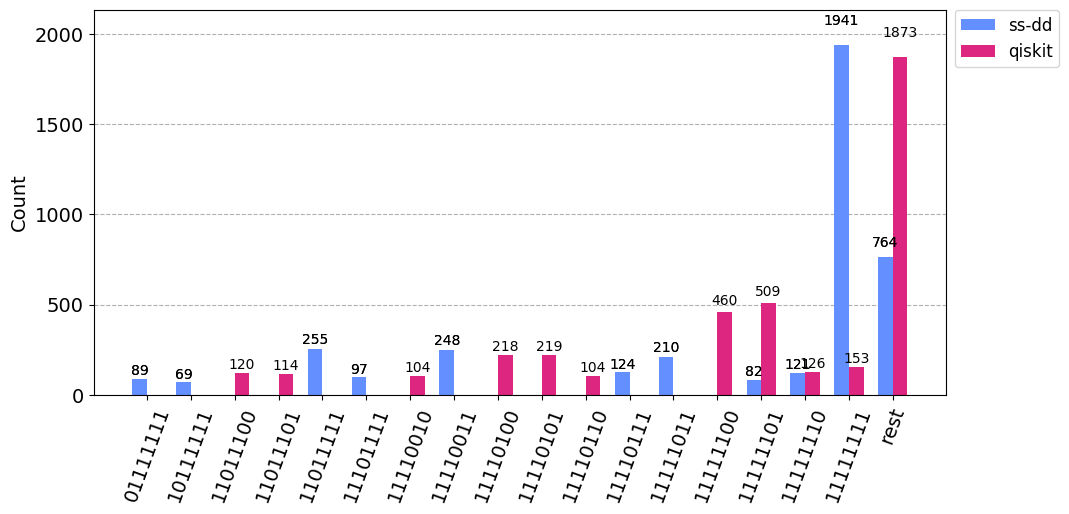
In this case, Superstaq with DD is once again able to provide outstanding improvement – more than 12.6x in terms of probability of ‘11111111’ success and about 25.3x in terms of relative strength.